
AI Model Pricing (LLM Inference)
This page outlines the pricing structure for all AI models available through AISA’s unified LLM inference API.
LLM usage is billed based on token consumption. Each request is charged separately for:
- Input tokens: the tokens included in your prompt
- Output tokens: the tokens generated by the model
All prices listed on this page are in USD per 1 million tokens (1M tokens).
How Token-Based Billing Works
When you send a request to an AI model:
- Your prompt is converted into input tokens.
- The model generates output tokens.
- Both input and output tokens are counted separately.
- The total cost is calculated using the model’s pricing.
The billing formula is:
Total Cost = (Input tokens ÷ 1,000,000 × Input price) + (Output tokens ÷ 1,000,000 × Output price)
For example:
- If a model charges $1.00 per 1M input tokens
- And you send 2,000 input tokens
- The input cost is:
2,000 ÷ 1,000,000 × 1.00 = $0.002
The same calculation applies to output tokens.
What Counts as Tokens?
Tokens represent fragments of text processed by the model. They may include:
- Words
- Punctuation
- Numbers
- Formatting characters
Longer prompts and longer outputs consume more tokens and therefore increase cost.
Streaming responses are billed the same way as non-streaming responses, based on total tokens generated.
Model Versions and Naming
Some models include version identifiers such as:
- Date-based versions (e.g.,
-2025-12-11) - “thinking” variants
- “mini” or “flash” variants
These represent distinct models and may have different pricing.
If a model is updated or replaced, pricing may differ between versions.
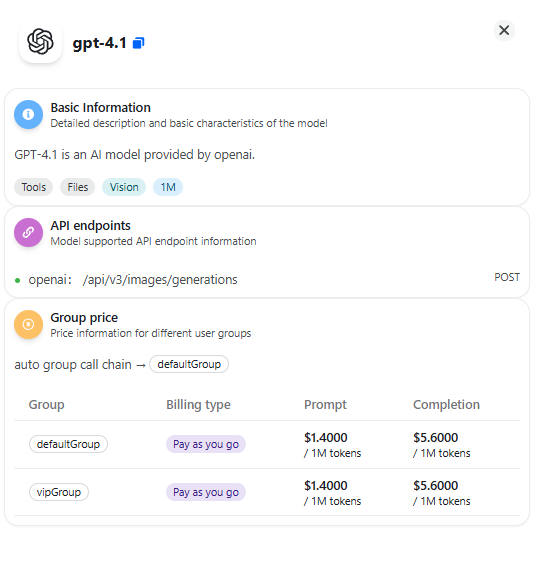
Group-Based Pricing
If your workspace uses multiple groups, pricing may vary by group.
Group-level pricing rules and ratios are applied automatically during billing. You can view the final calculated cost for each request in the Usage Logs page.
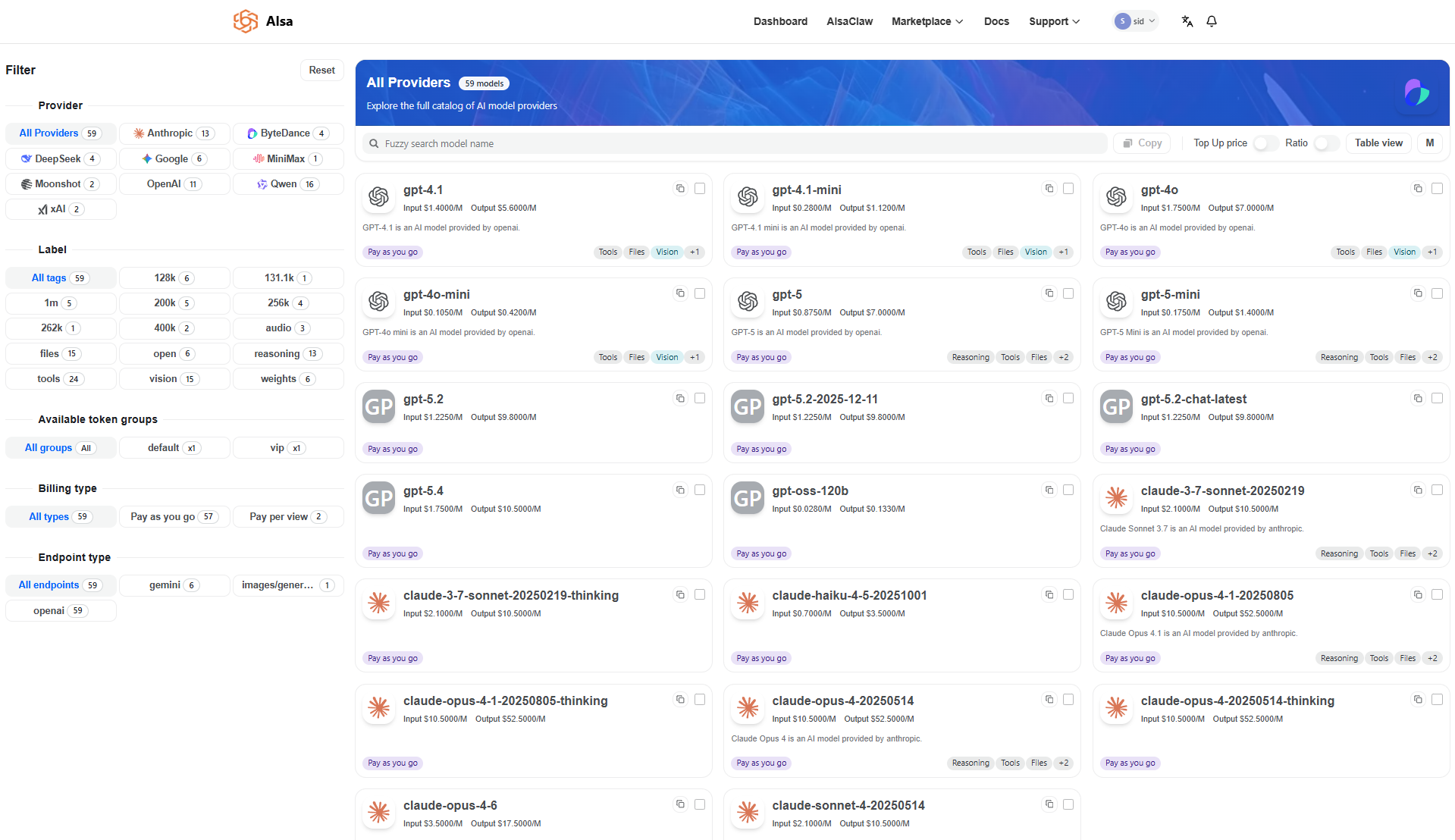
AI Model Pricing Table
AISA supports multiple types of AI models. Pricing is categorized based on how the model consumes compute:
- Token-based pricing: used for text and multimodal LLM inference.
- Media-based pricing: used for image generation and video generation models.
All token-based prices are listed per 1 million tokens (1M tokens).
Media models are priced per generated asset or per processing duration.
| Model Name | Input (USD / 1M tokens) | Output (USD / 1M tokens) |
|---|---|---|
| gpt-4.1 | 1.4 | 5.6 |
| gpt-4.1-mini | 0.28 | 1.12 |
| gpt-4o | 1.75 | 7 |
| gpt-4o-mini | 0.105 | 0.42 |
| gpt-5 | 0.875 | 7 |
| gpt-5-mini | 0.175 | 1.4 |
| gpt-5.2 | 1.225 | 9.8 |
| gpt-5.2-2025-12-11 | 1.225 | 9.8 |
| gpt-5.2-chat-latest | 1.225 | 9.8 |
| gpt-5.4 | 1.75 | 10.5 |
| gpt-oss-120b | 0.028 | 0.133 |
| claude-3-7-sonnet-20250219 | 2.1 | 10.5 |
| claude-3-7-sonnet-20250219-thinking | 2.1 | 10.5 |
| claude-haiku-4-5-20251001 | 0.7 | 3.5 |
| claude-opus-4-1-20250805 | 10.5 | 52.5 |
| claude-opus-4-1-20250805-thinking | 10.5 | 52.5 |
| claude-opus-4-20250514 | 10.5 | 52.5 |
| claude-opus-4-20250514-thinking | 10.5 | 52.5 |
| claude-opus-4-6 | 3.5 | 17.5 |
| claude-sonnet-4-20250514 | 2.1 | 10.5 |
| claude-sonnet-4-20250514-thinking | 2.1 | 10.5 |
| claude-sonnet-4-5-20250929 | 2.1 | 10.5 |
| claude-sonnet-4-6 | 2.1 | 10.5 |
| claude-sonnet-4-6-thinking | 2.1 | 10.5 |
| deepseek-r1 | 0.4018 | 1.6058 |
| deepseek-v3 | 0.2009 | 0.8029 |
| deepseek-v3-0324 | 0.2009 | 0.8029 |
| deepseek-v3.1 | 0.4018 | 1.2047 |
| gemini-2.5-flash | 0.21 | 1.75 |
| gemini-2.5-flash-lite | 0.07 | 0.28 |
| gemini-2.5-pro | 0.875 | 7 |
| gemini-3-pro-image-preview | 1.4 | 8.4 |
| gemini-3-pro-preview | 1.4 | 8.4 |
| gemini-3.1-pro-preview | 1.4 | 8.4 |
| grok-3 | 2.1 | 10.5 |
| grok-4 | 2.1 | 10.5 |
| kimi-k2-thinking | 0.4018 | 1.6058 |
| kimi-k2.5 | 0.4018 | 2.1077 |
| MiniMax-M2.5 | 0.21 | 0.84 |
| qwen-flash | 0.0225 | 0.18 |
| qwen-mt-flash | 0.072 | 0.2205 |
| qwen-mt-lite | 0.084 | 0.252 |
| qwen-plus-2025-12-01 | 0.28 | 0.84 |
| qwen-vl-max | 0.56 | 2.24 |
| qwen3-coder-480b-a35b-instruct | 1.05 | 5.25 |
| qwen3-coder-flash | 0.21 | 1.05 |
| qwen3-coder-plus | 0.7 | 3.5 |
| qwen3-max | 0.72 | 3.6 |
| qwen3-max-2026-01-23 | 0.72 | 3.6 |
| qwen3-omni-flash | 0.301 | 1.162 |
| qwen3-omni-flash-2025-12-01 | 0.301 | 1.162 |
| qwen3-vl-flash | 0.035 | 0.28 |
| qwen3-vl-flash-2025-10-15 | 0.035 | 0.28 |
| qwen3-vl-plus | 0.14 | 1.12 |
| qwen3-vl-plus-2025-12-19 | 0.14 | 1.12 |
| seed-1-6-250915 | 0.225 | 0.9 |
| seed-1-6-flash-250715 | 0.0675 | 0.27 |
| seed-1-8-251228 | 0.225 | 1.8 |
Image & Video Generation Pricing
Some models generate media rather than tokens. These models are billed per asset or processing duration.
Model Name | Pricing |
|---|---|
gemini-3-pro-image-preview | Token-based pricing (see token table) |
seedream-4-5-251128 | $0.036 per generated image |
qwen WAN 2.6 | $0.0688 per second (720p) |
Important Notes
- All prices are listed in USD.
- Text-based models are billed per input and output token.
- Image generation models are billed per generated image.
- Video generation models are billed per second of generated video.
- Pricing is usage-based and calculated per request.
- Model availability and pricing may change over time.
- Always refer to the Marketplace for the most up-to-date pricing information.
- The final billed amount for each request can be verified in Usage Logs.
Updated 4 days ago